Case Study
Building a Serverless AI Resume Analyzer
How Puter's per-user cost model and client-side PDF processing made it possible to build a fully serverless AI resume scorer — and why getting the prompt calibration right was the hardest engineering problem of the project.
Role
Solo Developer
Timeline
2 weeks
Type
Personal Project
Status
Shipped
Stack
React Router 7 · Puter.js · pdf.js · Zustand
Categories
5 scored
$0
Infrastructure cost
100%
Client-side processing
~5s
End-to-end analysis
Any LLM
Swappable AI model
01
The Problem
The Gap
- — Black-box scoring — Most resume tools give you a number with no explanation of how it was derived
- — False positives — Visually attractive resumes often score high even when ATS parsing would fail
- — Infrastructure cost — Running AI analysis at scale typically requires backend servers, queues, and storage — all expensive
- — Privacy concerns — Uploading a resume to an unknown server raises legitimate data handling questions
The Opportunity
- — Per-user quota — Puter's model means each user's AI usage is charged against their own account — zero marginal cost to the developer
- — Client-side PDF processing — pdf.js renders pages in the browser, so the resume never leaves the user's device
- — Transparent scoring — A well-designed prompt schema can return structured scores with category-level detail
- — Honest calibration — Prompt engineering can enforce realistic score distributions — preventing the inflation that makes most tools useless
02
How It Works
Three services, zero servers. Puter provides auth, file storage, and AI access — all scoped to the authenticated user. The browser handles PDF rendering. The result is a fully functional AI analyzer with no backend to maintain.
Application data flow
01 · Authentication
Puter OAuth
User authenticated — AI and storage quota scoped to their account
02 · User Inputs
Company Name
Job Title
Job Description
CV PDF
03 · Client-side Processing
pdf.js
Parses the PDF in-browser — extracts raw text and renders each page as a PNG at 4× scale. Nothing is uploaded to a server.
04 · State & Persistence
Zustand Store
Puter SDK wrapper — manages auth state, upload flow, and analysis results reactively
Puter
File Storage
Saves PDF + PNG assets per user
05 · AI Analysis
Prompt Builder
Combines TypeScript interface schema + company/role inputs + extracted PDF text into a calibrated system prompt
Puter AI Chat — GPT-5.2
Returns structured JSON matching the injected interface — score, ATS analysis, per-category feedback
Puter
KV Store → History View
Result JSON stored per application — user can browse all past analyses
06 · Output
Results View
Overall score, ATS panel, per-category accordion feedback
Scalability
Each user funds their own usage
Puter gives every authenticated user a free monthly quota — storage, compute, and AI credits. When a user runs an analysis, it draws from their quota, not the developer's.
This means the app scales to any number of users with zero marginal infrastructure cost. The $0/month figure isn't a temporary free tier — it's how the model works by design.
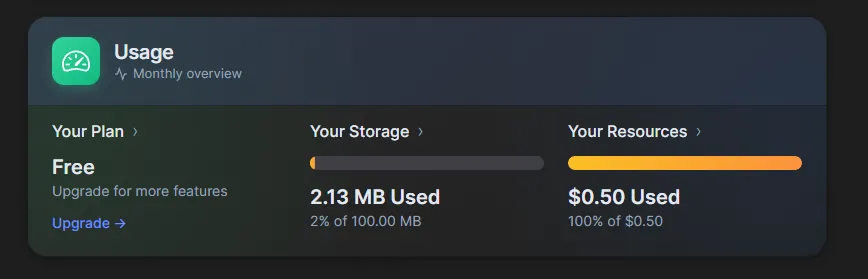
A user's Puter dashboard after running several analyses — their quota, not yours
03
Prompt Calibration — The Hard Part
ATS Severity Classification
The key insight was building a two-tier severity taxonomy — distinguishing between issues that merely look bad and issues that actually break ATS parsing.
Minor issues — small penalty each
Major issues — 10–15pt penalty each
Rule
2 or more MAJOR issues → overall score must fall below 50, regardless of content quality.
Score Scale
Precisely tailored
RESERVED for resumes written for this exact role
Strong
Well-structured, strong keyword density
Good
Clear structure, decent keyword match
Parseable but flawed
ATS can read it, notable issues present
Multiple problems
Structural failures hurt parsing
Severely broken
ATS cannot reliably parse
// Injected verbatim into the system prompt
"Do NOT inflate scores. A visually attractive resume with broken text extraction is still a BAD ATS resume. Score 91–100 is RESERVED for resumes precisely tailored to this specific job description."
// TypeScript interface injected verbatim as schema documentation
interface AnalysisResult {
overallScore: number; // 0–100
atsCompatibility: { score, issues, tips };
categories: { toneAndStyle, content, structure, skills };
} 04
Visual Walkthrough
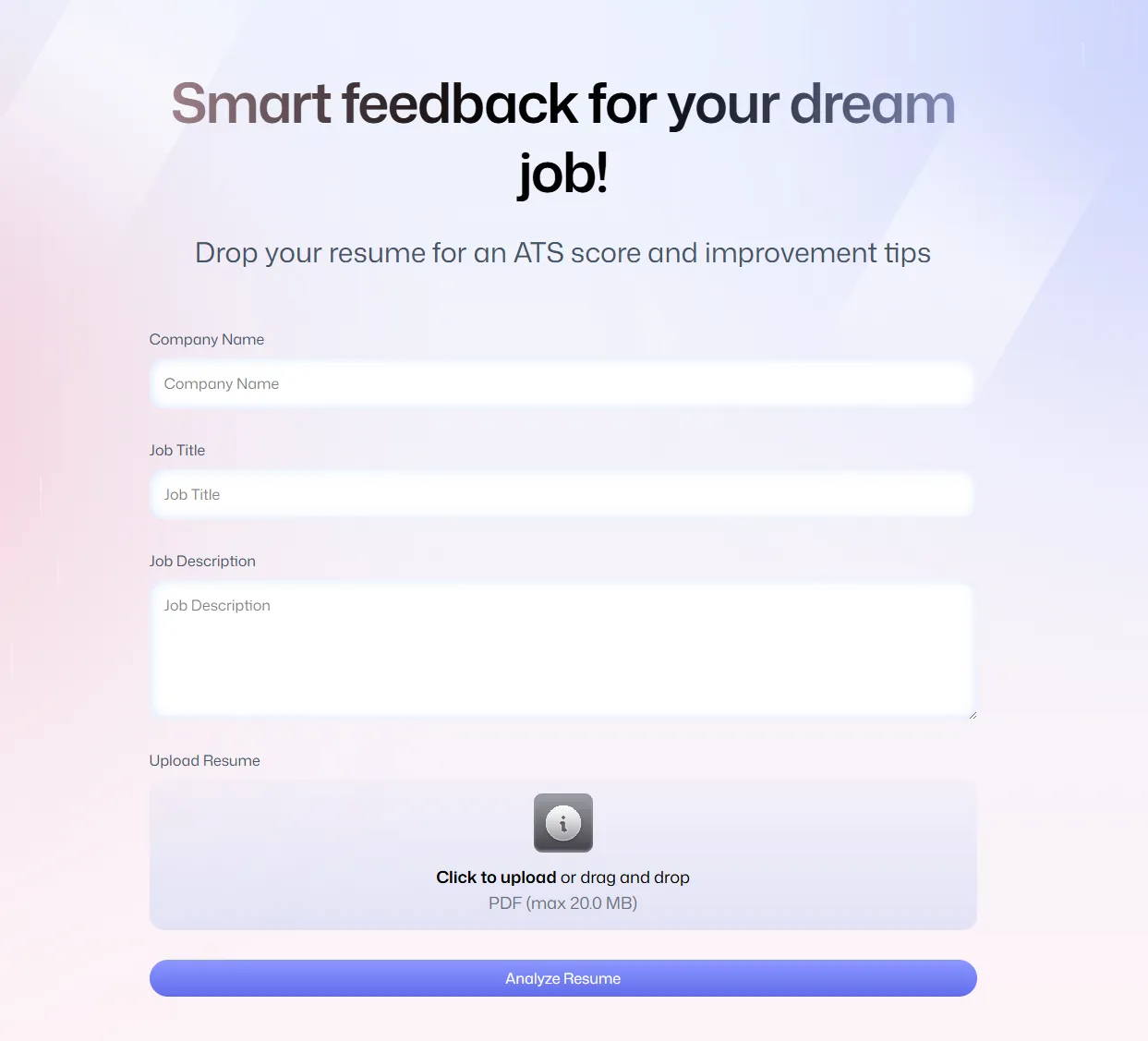
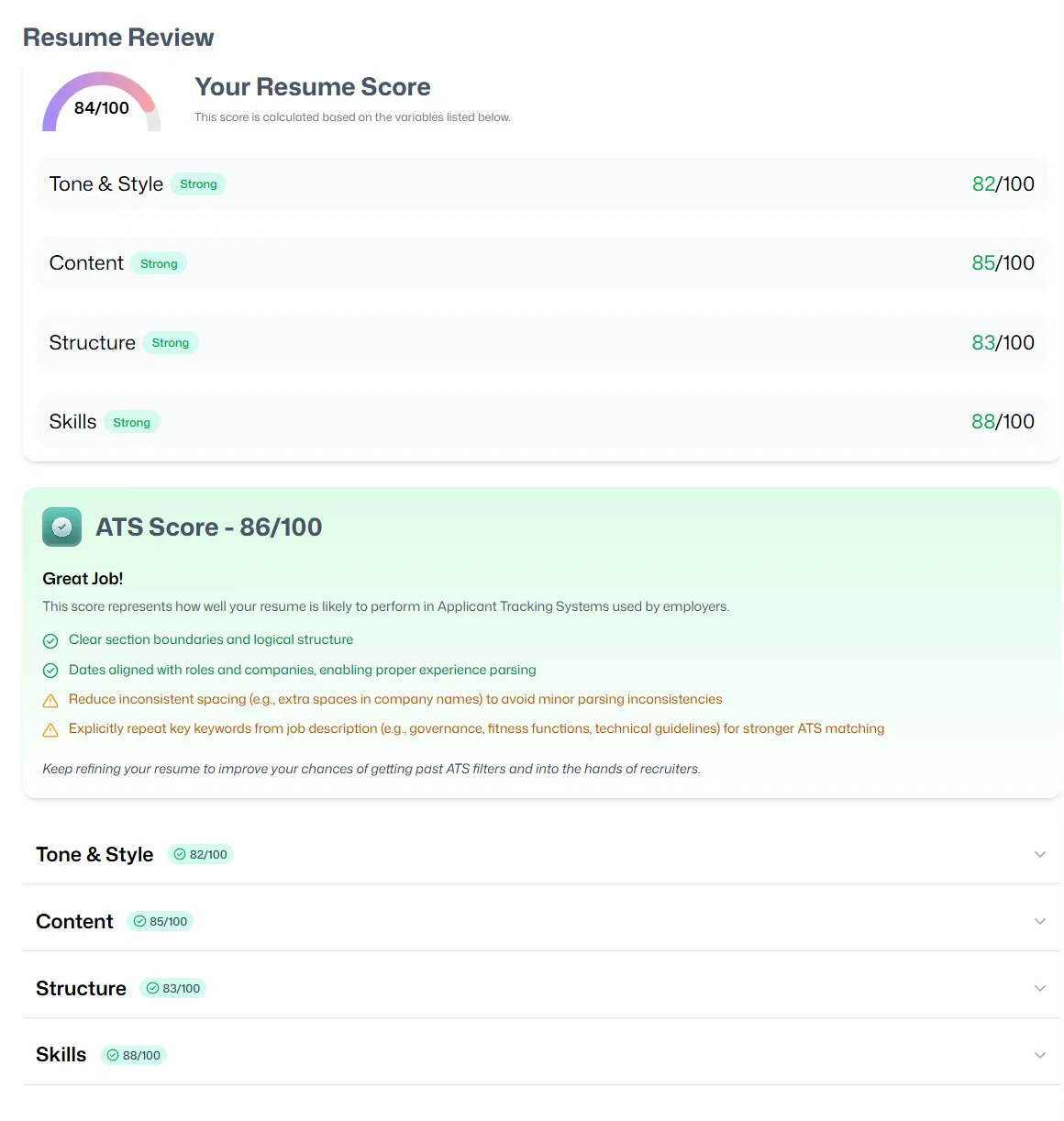
The upload form and the results panel — score breakdown, ATS compatibility, and per-category feedback
Loading experience
Clean UX to keep the user engaged while the scan runs
AI analysis takes ~5 seconds end-to-end. Rather than showing a spinner, the processing state breaks the wait into four visible steps — PDF rendering, text extraction, AI analysis, and result compilation.
A live status message tells the user exactly what's happening at each stage, while the animation keeps the interface feeling alive during the wait.


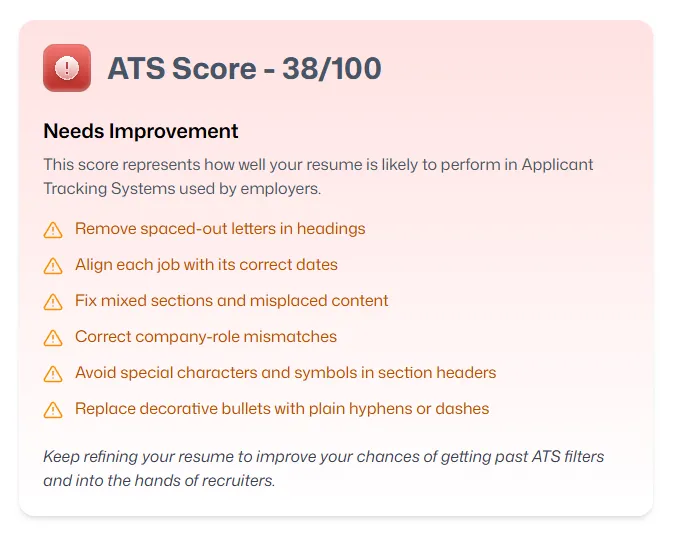
Honest feedback
Fair but unsparing when the resume earns it
A score that's always high is useless. The prompt calibration ensures the model penalises real structural problems — spaced letters, detached dates, multi-column layouts — that would genuinely break ATS parsing.
Some categories carry more weight than others — ATS compatibility in particular can override an otherwise decent resume. Every issue flagged comes with a concrete fix.
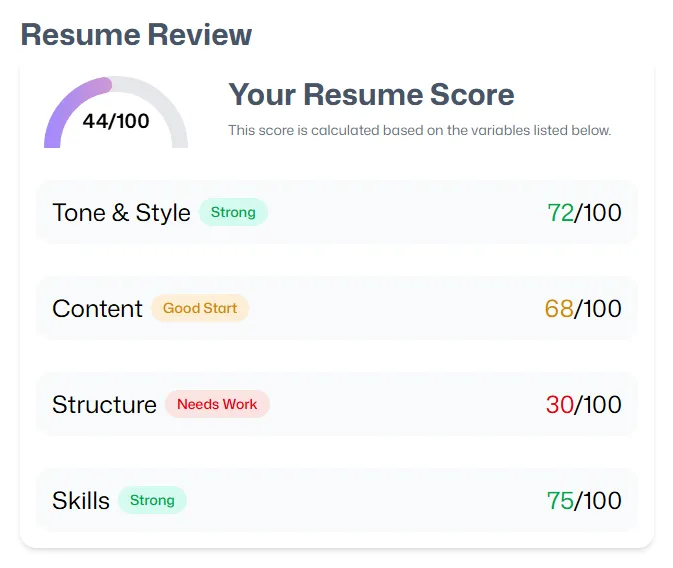
05
Key Technical Decisions
PDF Processing
Client-side via pdf.js
Privacy was a first-class constraint: the resume should never leave the user's browser. pdf.js renders each page to a canvas at 4× scale, then converts to PNG for AI analysis. This also eliminates a backend upload pipeline entirely.
Tradeoff
Adds bundle weight. Mitigated with dynamic import — pdf.js only loads when the user submits a file.
State Management
Zustand wrapping Puter SDK
Zustand provides a clean, typed reactive interface over Puter's SDK calls. The store handles auth state, upload progress, analysis results, and error states — all with Redux DevTools support for debugging.
Tradeoff
A thin abstraction to maintain if Puter's SDK API changes, but the coupling is intentionally shallow.
AI Response Schema
TypeScript interface injected as prompt documentation
Injecting the TypeScript interface directly into the system prompt reliably constrains the model to return exactly the expected JSON structure. No post-processing or fallback parsing needed.
Tradeoff
More prompt tokens per request, but the consistency benefit far outweighs the marginal cost.
Unique IDs
crypto.randomUUID() for serverless ID generation
With no backend, there's no database sequence or UUID service. crypto.randomUUID() is collision-resistant and available in all modern browsers — sufficient for per-user session and file identification in Puter's KV store.
Tradeoff
None meaningful at this scale.
06
Reflection
What I Learned
The technical implementation took a day. Getting the scoring to behave honestly took the rest of the project.
- — Prompt iteration is engineering — it requires hypotheses, tests, and measurable outcomes, not intuition
- — Client-side processing is underrated — browser APIs are powerful enough for tasks most developers reflexively push to a server
- — Zustand + external SDK pattern is repeatable — clean abstraction over third-party state is worth the extra file
Results
Infrastructure cost
$0 / month
Puter's per-user model means the developer pays nothing at any scale
End-to-end processing
~5 seconds
PDF render + AI analysis + result display from submit to results
Privacy
Zero server exposure
Resume content never leaves the user's browser — processed entirely client-side
Resumer demonstrated that the combination of Puter's platform and modern browser APIs can eliminate entire infrastructure tiers. The project wasn't primarily about the AI feature — it was about proving that tailored prompt engineering, not backend complexity, is what makes AI-powered tools genuinely useful.